

.jpg?length=750&name=5028%20(1).jpg)
Up, down, Detroit, charm, inside out, strange, London, bottom up, outside in, mockist, classic, Chicago….
Do you remember the questions on standardized tests where they asked you to pick the thing that wasn’t like the others? Well, this isn’t a fair example as there are really two distinct groups of things in that list, but the names of TDD philosophies have become as meaningless to me as the names of quarks. At first I thought I’d use this post to try to sort it all out, but then I decided that I’m not the Académie française of TDD school names and I really don’t care that much. If the names interest you, I can suggest you read TDD – From the Inside Out or the Outside In. I’m not convinced that the author has all the grouping right (in particular, I started learning TDD from Kent Beck, Ron Jeffries and Bob Martin in Chicago, which is about as classic as you can get, and it was always what she calls outside in but without using mocks), but it’s a reasonable introduction.
Still, it felt like it was time to think about TDD again, so instead I went back to Ron Jeffries Thoughts on Mocks and a comment he made on the subject in his Google Groups Forum. In the posting, Ron speculated that architecture could push us a particular style of TDD. That feels right to me. He also suggested that writing systems that are largely “assemblies of OPC (Other People’s Code)” “are surely more complex” than the monolithic architectures that he’s used to from Smalltalk applications and that complexity might make observing the behavior of objects more valuable. That idea puzzles me more.
My own TDD style, which is probably somewhere between the Detroit school, which leans towards writing tests that don’t rely on mocks, and London schools, which leans towards using mocks to isolate each unit of the application, definitely evolved as a way to deal with the complexity I faced in trying to write all my code using TDD. When I first started out, I was working on what I believe would count as a monolithic application in that my team wrote all the code from the UI back to right before the database drivers. We started mocking out the database not particularly to improve the performance of the tests, but because the screens were customizable per user, the data for which was in a database, and the actual data that would be displayed was stored across multiple tables. It was really quite painful to try to get all the data set up correctly and we had to keep a lot more stuff in mind when we were trying to focus on getting the configurable part of the UI written. This was back in 1999 or 2000, and I don’t remember if someone saw an article on mocking, but we did eventually light on the idea of putting in a mock object that was much easier to set up than the actual database. In a sense, I think this is what Ron is talking about in the “Across an interface” section of his post, but it was all within our code. Could we have written that code more simply to avoid the complexity to start with? It was a long time ago and I can’t say whether or not I’d take the same approach now to solving that same problem, but I still do find a lot of advantages in using mocks.
I’ve been wanting to try using a NoSQL database and this seemed like a good opportunity to both try that technology and, after I read Ron’s post, try writing it entirely outside-in, which I always do anyway, and without using mocks, which is unusual for me. I started out writing my front-end using TDD and got to the point that I wanted to connect a persistence mechanism. In a sense, I suppose the simplest thing that could possibly work here would have been to keep my data in a flat file or something like that, but part of my purpose was to experiment with a NoSQL database. (I think this corresponds to the reasonably common situation of “the enterprise has Oracle/MS SQL Server/whatever, so you have to use it.) I therefore started with one of the NoSQL implementations for .NET. Everything seemed fine for my first few unit tests. Then one of my earlier tests failed after my latest test started passing. Okay, this happens. I backed out my the code I’d just written to make sure the failing test started passing, but the same test failed again. I backed out the last test I’d written, too. Now the failing test passed but a different one failed. After some reading and experimentation, I found that the NoSQL implementation I’d picked (honestly without doing a lot of research into it) worked asynchronously and it seemed that I’d just been lucky with timing before they started randomly failing. Okay, this is the point that I’d normally turn to a mocking framework and isolate the problematic stuff to a single class that I could either put the effort into unit testing or else live with it being tested through automated customer tests.
Because I felt more strongly about experimenting with writing tests without using mocks than with using a particular NoSQL implementation, I switched to a different implementation. That also proved to be a painful experience, largely because I hadn’t followed the advice I give to most people using mocks, which is to isolate the code for setting up the mock into an individual class that hides the details of how the data is set up. Had I been following that precept now that I was accessing a real persistence mechanism rather than a mock, I wouldn’t have needed to change my tests to the same degree. The interesting thing here was that I had to radically change both the test and the production code to change the backing store. As I worked through this, I found myself thinking that if only I’d used a mock for the data access part, I could have concentrated on getting the front-end code to do what I wanted without worrying about the persistence mechanism at all. This bothered me enough that I finally did end up decoupling the persistence mechanism entirely from the tests for the front-end code and focus on one thing at a time instead of having to deal with the whole thing at once. I also ended up giving up on the NoSQL implementation for a more familiar relational database.
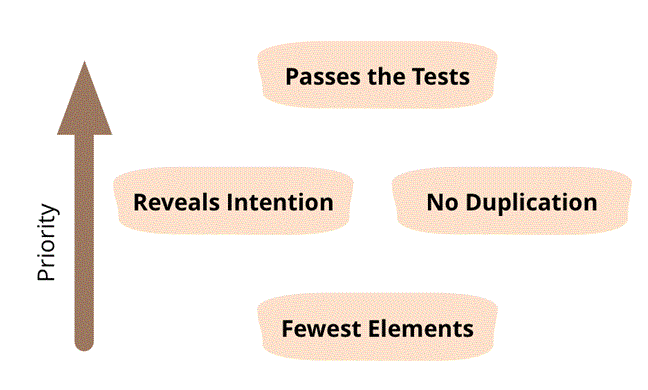
Image from http://martinfowler.com/bliki/BeckDesignRules.html
So, where does all this leave my thoughts on mocks? Ron worried in his forum posting that using mocks creates more classes than testing directly and thus make the system more complex. I certainly ended up with more classes than I could have, but that’s the lowest priority in Ken Beck’s criteria for simple design. Passing the tests is the highest priority, and that’s the one that became much easier when I switched back to using mocks. In this case, the mocks isolated me from the timing vagaries of the NoSQL implementations. In other cases, I’ve also found that they help isolate me from other random elements like other developers running tests that happen to modify the same database tables that are modifying. I also felt like my tests became much more intention-revealing when I switched to mocks because they talked in terms of the high-level concepts that the front-end code dealt with instead of the low-level representation of the data of the persistence code needed to know about. This made me realize that the hard part was caused by the mismatch between the way the persistence mechanism (either a relational database or the document-oriented NoSQL database that I tried) and the way I thought of the data in my code. I have a feeling that if I’d just serialized my object graph to a file or used an object-oriented database instead of a document-oriented database, that complexity would go away. That’s for a future experiment, though. And, even if it’s true, I don’t know how much I can do about it when I’m required to use an existing persistence mechanism.
Ron also worried that the integration between the different components is not tested when using mocks. As Ron puts it in his forum message: “[T]here seems to be a leap of faith made: it’s not obvious to me that if we know that A sends the right messages to Mock B, and B sends the right messages to Mock A, A and B therefore work. There’s an indirection in that logic that makes me nervous. I want to see A and B getting along.” I don’t think I’ve ever actually had a problem with A and B not getting along when I’m using mocks, but I do recall having a lot of problems with it when I had to map between submitted HTML parameters and an object model. (This was back when one did have to write such code oneself.) It was just very to mistype names on either side and not realize it until actual user testing. This is actually the problem that led us to start doing automated customer testing. Although the automated customer tests don’t always have as much detail as the unit tests, I feel like they alleviate any concerns I might have that the wrong things are wired together or that the wiring doesn’t work.
It’s also worth mentioning that I really don’t like the style of using mocks that really just check if a method was called rather than it was used correctly. Too often, I see test code like:
mock.Stub(m => m.Foo(Arg.Is.Anything, Arg.Is.Anything)).Return(0);
…
mock.AssertWasCalled(m => m.Foo(Arg.Is.Anything, Arg.Is.Anything));
I would never do something like this for a method that actually returns a value. I’d much rather set up the mock so that I can recognize that the calling class both sent the right parameters and correctly used the return value, not just that it called some method. The only time I’ll resort to asserting a method was called (with all the correct parameters), is when that method exists only to generate a side-effect. Even with those types of methods, I’ve been looking for more ways to test them as state changes rather than checking behavior. For example, I used to treat logging operations as side-effects: I’d set up a mock logger and assert that the appropriate methods were called with the right parameters. Lately, though, with Log4Net, I’ve been finding that I prefer to set up the logger with a memory appender and then inspect its buffer to make sure that the message I wanted got logged at the level I wanted.
In his Forum posting, Ron is surely right in saying about the mocking versus non-mocking approaches to writing tests: “Neither is right or wrong, in my opinion, any more than I’m right to prefer BMW over Mercedes and Chet is wrong to prefer Mercedes over BMW. The thing is to have an approach to building software that works, in an effective and consistent way that the team evolves on its own.” My own style has certainly changed over the years and I hope it will continue to adapt to the circumstances in which I find myself working. Right now I find myself working with a lot of legacy code that would be extremely hard to get under test if I couldn’t break it up and substitute mocks for collaborators that are nearly impossible to get set up correctly. Hopefully I’ll also be able to use mocks less, as I find more projects that allow me to avoid the impedance between the code’s concept of the model and that of external systems.